知识点:
- 网页的内容由 HTML 决定
- 找某条微博配图的链接,就是找该条微博的 HTML 中配图的链接
- 如何用浏览器查询微博的配图链接
- 微博网页端和移动端的链接区别
在微博上有些人会发多长图式的内容,其中有一些还挺值得收藏。比如这是一条来自 @宁亦迟 的微博:
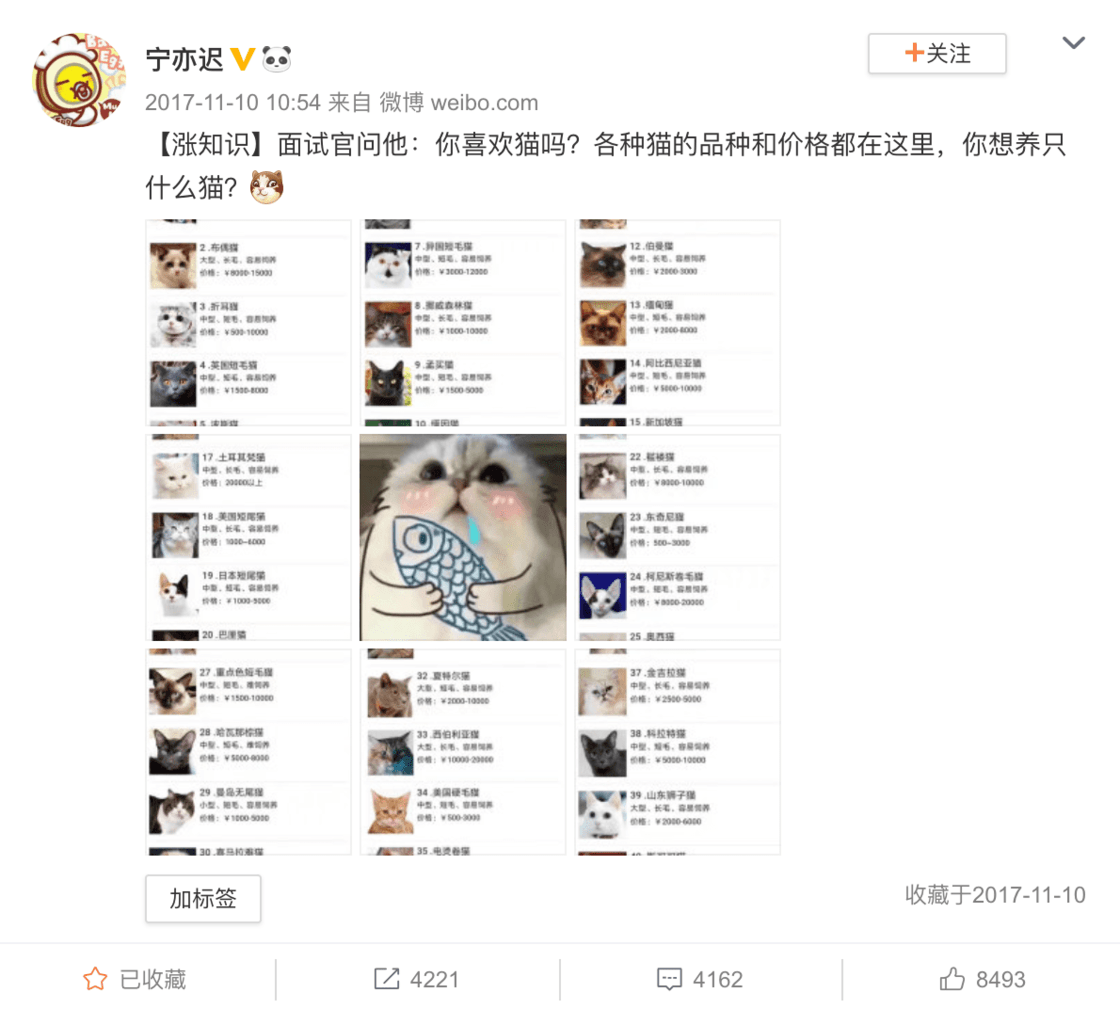
图片里介绍了猫的种类、价格以及简介。
像这样的微博,仅仅在微博上收藏是不够的,因为保不齐作者哪天不开心清微博,又或者微博某一天倒闭不再运营。所以最好的方法是将其保存到本地。但其实保存到相册还不够好,如果能带上特定的名字保存到文件里,就更方便归档和查询,像是这样:
存档多张微博配图
要做一个这样的捷径,要学会两样东西:
- 如何扒网页:给你一个网址,你能从中获取你需要的东西。
- 如何把它做成捷径。
这两样我们分两篇文章讲,这篇先来看前一个——如何扒网页。
初步理解扒网页的思维
对于一个此前从来没有相关知识的人来说,要想扒网页,就要知道两件事:
- 我们是在什么东西上扒?
- 我们要扒的是什么?
那么对于这两个问题,如果我们要做一个「批量扒微博图片」的捷径的话,它对应的答案就是:
- 在 HTML 文件上扒。
- 扒的是图片文件。
首先来理解一下「在 HTML 文件上扒」这句话。关于 HTML 我们已经在《专栏:为什么 Markdown 会流行?》中进行了简单的介绍,在这里,我们要知道的点是——我们访问的网页一般都是由 HTML 语言写的。一个网页中的文本、视频、图片等内容,都可以还原为 HTML 的代码,一个网页一般就是一个 HTML 文件。
而 HTML 文件是纯文本的,所以我们可以像在文章中查找错别字那样,去在一个 HTML 文件里查找我们需要的字段。
所以接下来我们就很容易理解「扒的是图片」这句话了。图片如果用 HTML 表示,一定是一堆带有格式后缀名的字符,比如说 手动狗头.jpg。一般来说我们要下载的网页上的图片的后缀名,都是比较常见的后缀名,如 .jpg、.png 等。而微博里的高清图,一般都是 .jpg 结尾的。
但是一个网页里可能有非常多以 .jpg 结尾的图片。拿微博来说,除了我们想下载的微博配图以外,微博图标、个人头像、评论头像等等都有可能是 .jpg 图片。所以在这里,我们要扒的,仅仅是微博配图,也就是说,我们要找到微博配图的链接特征。
这样,我们就把工作的范围缩小到了——当我们想获得一条微博里的所有图片时,只要获取到这条微博链接下的 HTML 文件中,符合微博配图链接特征的 .jpg 文件。
接下来我们就按这个思路,来获取微博中的图片。
找到微博图片链接的规律
我们已经知道,在 HTML 文件中找图片链接,就像是在一篇文章里找错字。不过,找错字的时候我们一般知道错字是什么,用的都是搜索和替换。而在 HTML 文件里找图片链接用的思路也一样,肯定也是搜索出来更效率,那么我们到底要搜什么呢?
更恰当的问题是,符合微博配图链接特征的 .jpg 文件,它的链接到底长什么样呢?
要回答这个问题,我们可以先借助桌面浏览器来达到目的。
在电脑上的 Safari 或者 Google 上打开一个网页(比如说效果演示视频里的网页):右键空白处,在弹出菜单的底部,会出现「审查元素(Inspect Element)」或「Inspect」的字样1 :

选择这个「Inspect」就会在网页里弹出一个看起来很专业的界面:
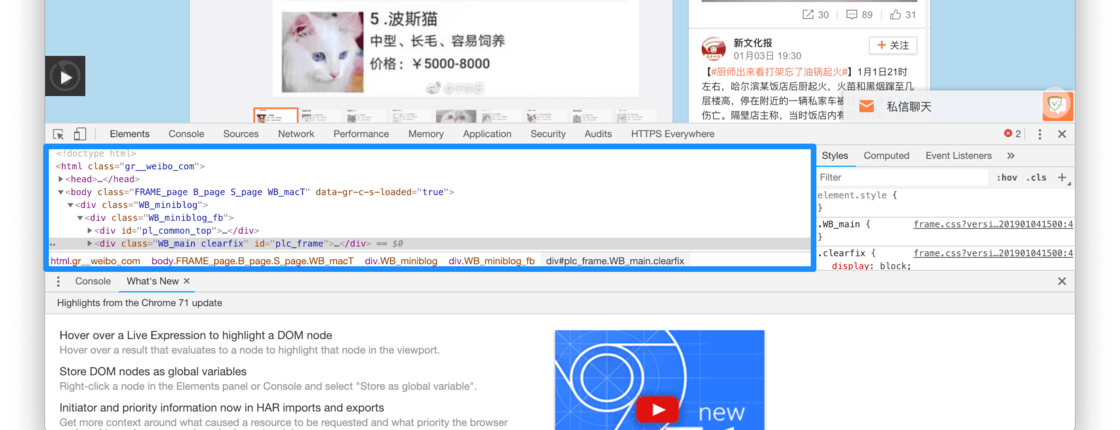
而这个界面的左上角这个部分,就是这个网页的 HTML。
而且如果我们在左上角这个区域来回滚动鼠标,就会发现网页部分会有高亮区域不断变换:
通过高亮部分判断是否需要代码
在这个位置,如果我们发现高亮的地区是我们需要的部分,就说明我们鼠标悬停的那一段代码是我们需要的。当我们层层打开我们需要的代码,最终就能找到我们需要的图片的链接。在演示视频的最后我们就找到了图片里的链接:
wx1.sinaimg.cn/mw690/6682c0e7gy1flcswo7pr1j20cn0hxgnc.jpg而且我们发现,它确实是 .jpg 结尾。
如果我们使用这个方法去找其它的配图(有的微博不止一个配图),你会发现这些链接都含有 sinaimg.cn/mw690/ 这个部分。
想要验证的话有多种方法,在 Chrome 上最方便的方法是:在网页上右键空白区域,选择「View Page Source」,这就相当于把 HTML 文件完全打开给我们看了:
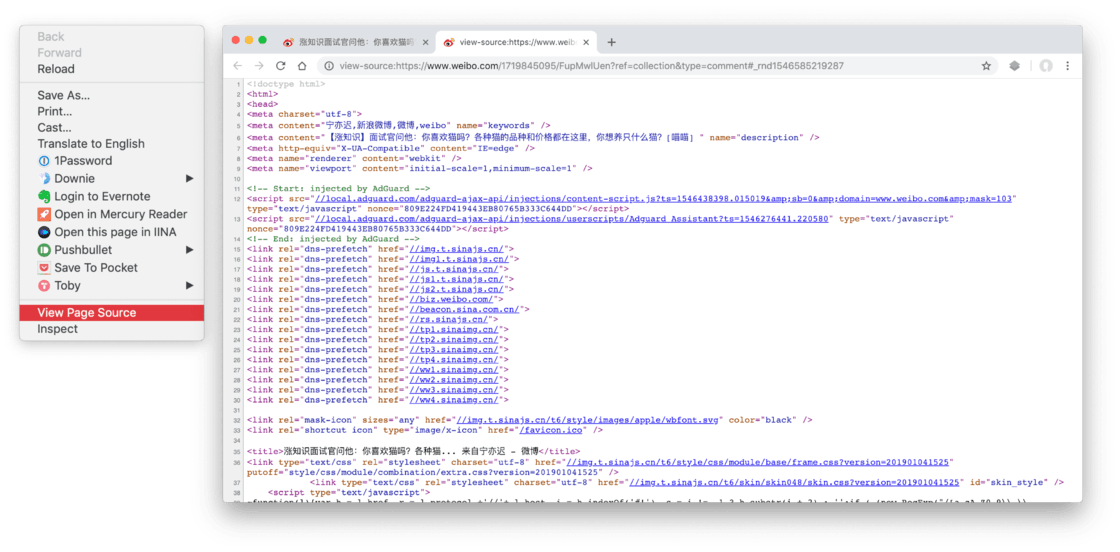
这时我们在页面里用快捷键 ⌘Command-F 打开搜索功能,来搜索 sinaimg.cn%2Fmw2 ,就会发现正好有 9 个结果,对应 9 图:
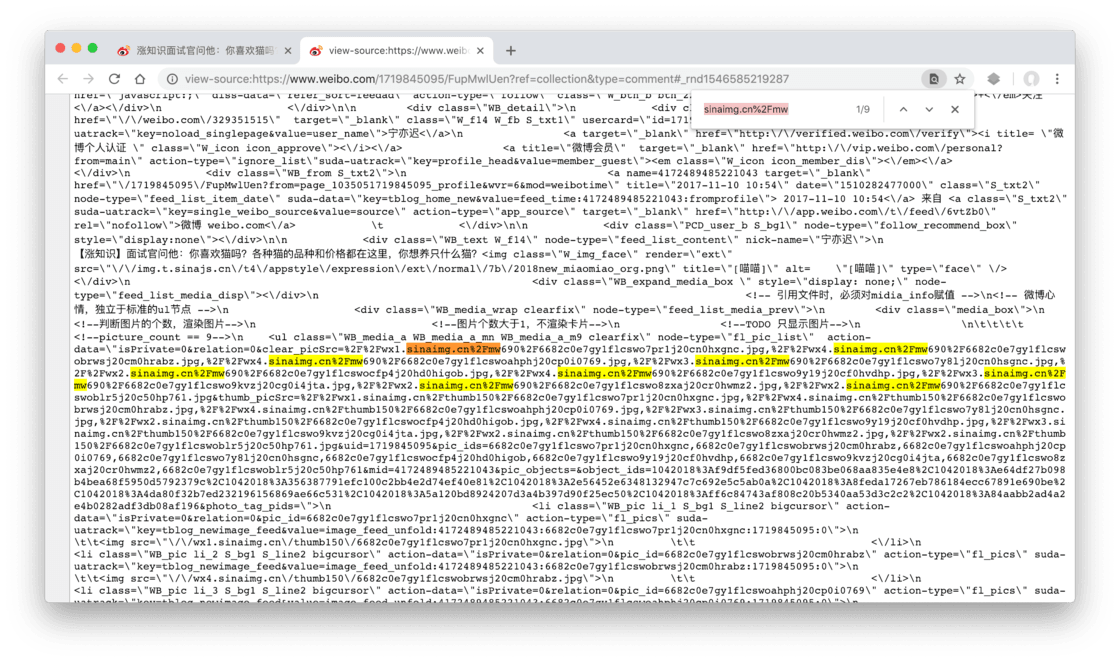
这样我们就几乎可以确定,当我们需要获取一条微博里的所有图片时,只要获取它的 HTML 文件,再在里面找带有 sinaimg.cn/mw690/ 的链接即可。
移动端与桌面端的区别
在上一步,我们已经掌握了如何获取微博的配图链接。但是仍然有一个问题需要注意,那就是移动端的微博链接和桌面端的微博链接不一样,它们显示出来的内容也不同。
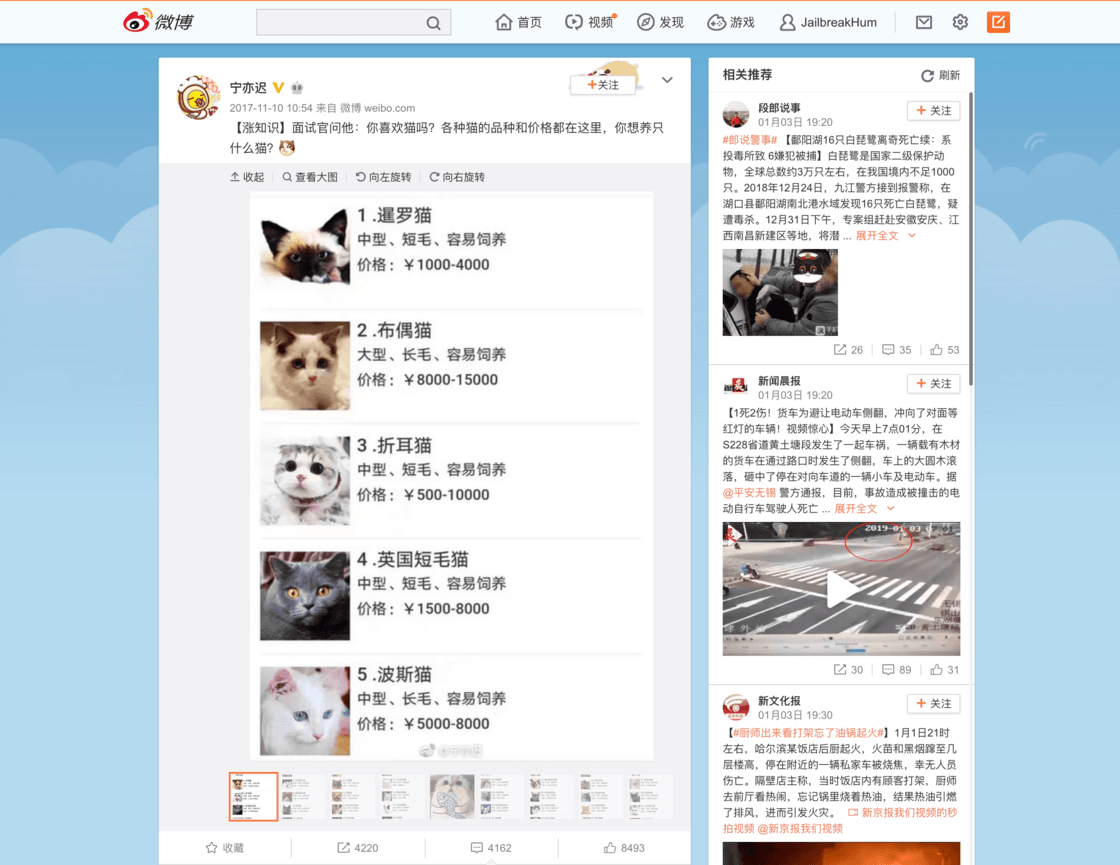
桌面端的微博链接是这样的:https://www.weibo.com/1719845095/FupMwlUen?ref=collection&type=comment#_rnd1546585219287。网页里的元素也很多:
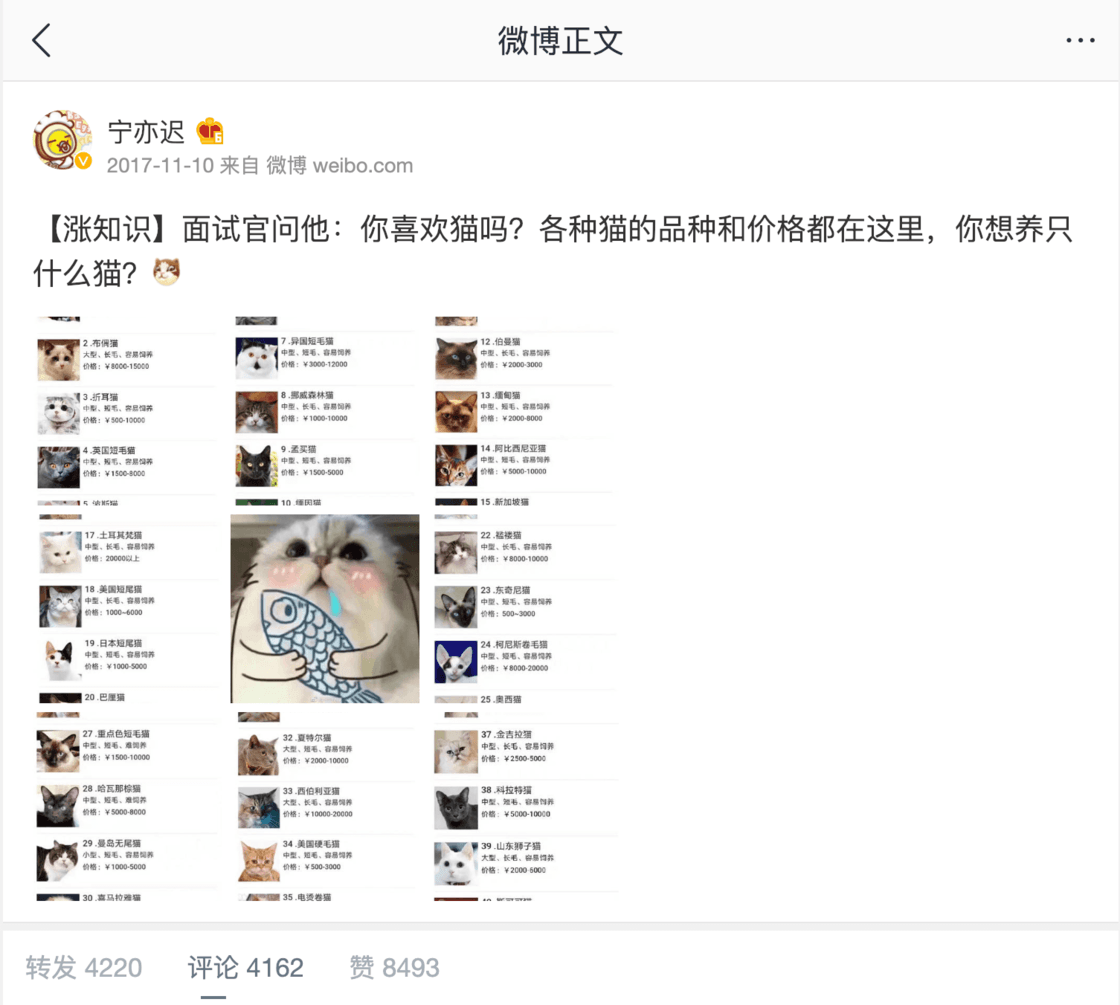
而移动端复制出来的链接比较干净:https://m.weibo.cn/status/4172489485221043,界面也比较干净:
因为我们要在移动端复制链接,所以就需要了解移动端获取的微博链接的 HTML 文件有没有什么变化,我们之前找到的微博配图的链接规律还是否适用?
解决这些问题非常容易,我们只要在移动端复制一条微博的链接,比如说还是之前猫的那条(https://m.weibo.cn/status/4172489485221043),再在 Chrome 里用「Inspect」一步一步找到图片对应的链接即可,过程我就不再重复了,我们只看结果。
只看结果我们会发现这样一个情况:
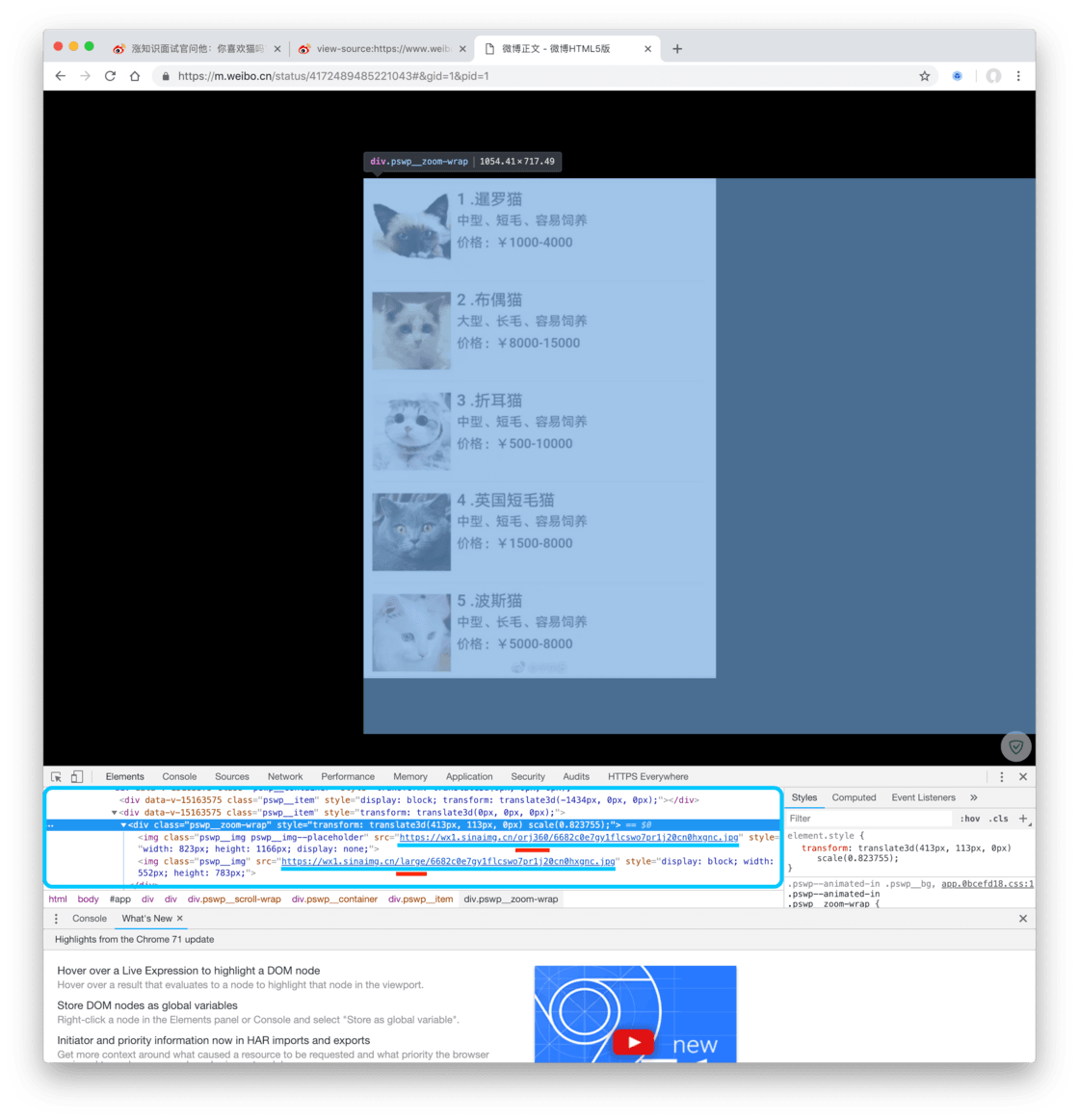
在表示同一张图片的区域,我们发现了两个链接。这两个链接几乎完全一样,而且还都有之前我们发现过的 sinaimg.cn/ 这个部分,但之前我们发现的 sinaimg.cn/mw690/ 这个部分里,mw690 变了,在前一个链接里是 orj360 而后一个链接里同一个位置是 large。而我们如果点开这两个链接,就会发现,orj360 那张图比较小,比较不清晰。
其实带有 orj360 的链接都是缩略图,而我们真正想获取的原图都在带 large 的链接里。这样,我们就了解了如何获取移动端微博链接中的微博配图的原图。那就是,只要我们从微博链接中的 HTML 文件中找到带有 sinaimg.cn/large/ 的链接,那它就一定是微博配图。
小结
至此,面对扒网页这个问题,我们已经可以回答最初那两个问题:
- 我们要从什么地方扒?
- 我们要扒的是什么?
在这个探索的过程中,比较重要的能力有两个:
- 发现规律:要找到一个比较通用的解决方法。
- 验证规律:当我们自认为发现了一个通用的解决方法时,要验证它是不是在各种情况下都适用。
只要拥有了这两个能力,再掌握了文中的方法,你就具备了扒网页的能力。接下来,我们要解决的问题就是如何用捷径来实现我们的思路。
- 1Safari 需要在 Safari 的偏好设置中打开「Show Develop menu in menu bar」。
- 2链接里的 / 是 斜线(/)被 URL 编码后代替的字符,也就是说你可以把 / 看成斜线(/)。可以搜索「URL 编码」或「URL Encode」了解相关知识。